|
|
前言
我们用爬虫爬取到网上的数据后,需要将数据存储下来。数据存储的形式多种多样,其中最简单的一种是将数据直接保存为文本文件,如TXT、JSON、CSV、EXCEL,还可以将数据保存到数据库中,如常用的关系型数据库MySQL和非关系型数据库MongoDB,下面以一个具体爬取案例为例分别介绍这几种数据存储方式的实现。
案例介绍
我们有时想要学习某个知识点,经常在一些在线课程网站查找一些课程,以网易云课堂为例,在搜索框中输入关键词python,点击搜索,会出现很多关于Python的课程,我们需要将这些课程信息保存下来。
在Google浏览器中右击选择“检查”,通过分析得知,网页上面的课程数据是通过一个ajax接口请求的,请求这个接口便可以获取到想要的信息。
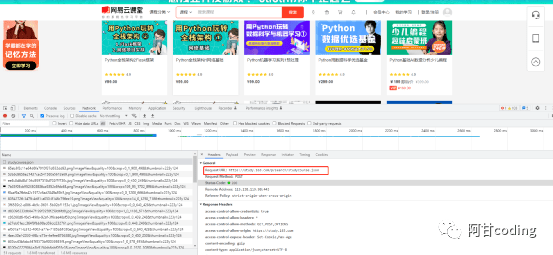
数据为Json格式,代码如下:
import requests
def get_json(index):
url = 'https://study.163.com/p/search/studycourse.json'
plyload = {
'activityId': 0,
'advertiseSearchUuid': "0c2689fb-db3c-4e76-b413-6dae72725b0d",
'keyword': "python",
'orderType': 50,
'pageIndex': index,
'pageSize': 50,
'priceType': -1,
'qualityType': 0,
'relativeOffset': 150,
'searchTimeType': -1,
'searchType': 10
}
heads = {
'accept': 'application/json',
'content-type': 'application/json',
'origin': 'https://study.163.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
try:
response = requests.post(url,json=plyload,headers=heads)
content_join = response.json()
if content_join and content_join['code'] == 0:
return content_join
return None
except Exception as e:
print('出错了')
print(e)
return None
def get_content(content_join):
if 'result' in content_join:
return content_join['result']['list']
TXT文本数据存储
将数据保存为txt文件的操作非常简单,而且txt文本几乎兼容任何平台,但是这种方式有个缺点,就是不利于检索,如果对检索数据要求不高,追求方便的话,可以采用txt文本存储。代码如下:
if __name__ == '__main__':
totalPageCount = get_json(1)['result']['query']['totlePageCount']
file = open('python课程.txt', 'w', encoding='utf-8')
for index in range(1, totalPageCount + 1):
content = get_content(get_json(index))
for item in content:
file.write(f"商品ID:{item['productId']}\n")
file.write(f"商品名称:{item['productName']}\n")
file.write(f"机构名称:{item['lectorName']}\n")
file.write(f"评分:{item['score']}\n")
file.write(f"{'='*50}\n")
file.close()
保存的数据如下图所示:
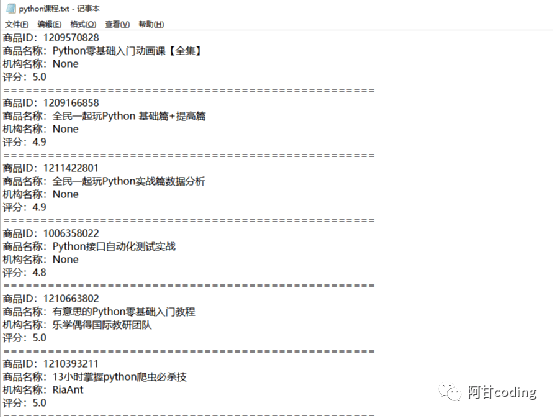
JSON文件存储
JSON全称为JavaScript Object Notation,通过对象和数组的组合来表示数据,虽构造简洁但是结构化程序非常高,是一种轻量级的数据交换格式。
代码如下:
import json
def save_data(item):
try:
name = item['productName']
data_path = f'../results/{name}.json'
json.dump(item,open(data_path,'w',encoding='utf-8'),ensure_ascii=False,indent=2)
except Exception as e:
print(f'{name}:出错了')
if __name__ == '__main__':
totalPageCount = get_json(1)['result']['query']['totlePageCount']
for index in range(1, totalPageCount + 1):
content = get_content(get_json(index))
for item in content:
save_data(item)
保存的数据如下:
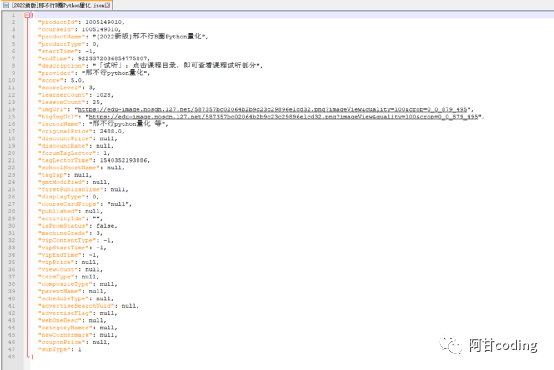
CSV文件存储
CSV全称为Comma-Separated Values,中文叫做逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。CSV是一个字符序列,可以是任意数目的记录组成,各条记录以某种换行符分割开。
代码如下:
import csv
if __name__ == '__main__':
totalPageCount = get_json(1)['result']['query']['totlePageCount']
file = open('python课程.csv', 'w')
head = ['商品ID', '商品名称', '机构名称', '评分']
writer = csv.writer(file, delimiter=',')
writer.writerow(head)
for index in range(1, totalPageCount + 1):
content = get_content(get_json(index))
for item in content:
list = [item['productId'], item['productName'], item['lectorName'], item['score']]
writer.writerow(list)
file.close()
保存的数据如下:
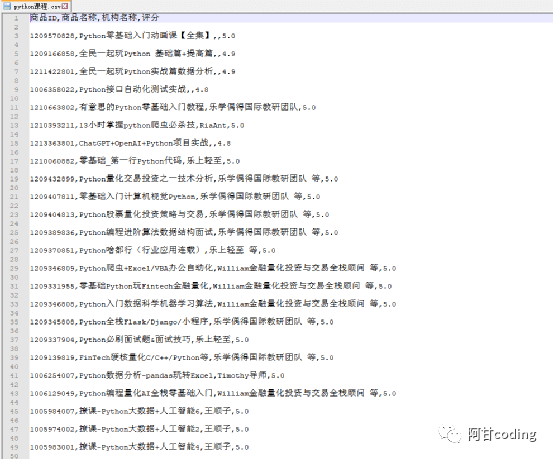
Excel文件存储
Excel是我们经常使用的一款电子表格软件,它可以非常直观的展示和分析数据。但是Excel存储数据有数量限制,xls格式的Excel文件一个工作表最多可以存储65536行数据。Xlsx格式的Excel文件一个工作表最多可以存储1048576行数据,可以满足绝大多数的存储要求。
代码如下:
import openpyxl
def save_excel(index):
content = get_content(get_json(index))
for item in content:
list = [item['productId'],item['productName'],item['lectorName'],item['score']]
sheet.append(list)
if __name__ == '__main__':
print('开始执行')
wb_name = 'python课程.xlsx'
wb = openpyxl.Workbook()
sheet = wb.create_sheet('first_sheet')
excel_head = ['商品ID','商品名称','机构名称','评分']
sheet.append(excel_head)
totalPageCount = get_json(1)['result']['query']['totlePageCount']
for index in range(1,totalPageCount+1):
save_excel(index)
wb.save(wb_name)
保存的数据如下:

MySQL存储
MySQL是一种关系型数据库,关系型数据库是基于关系模型的数据库,是通过二维表来保存数据,每一列代表一个字段,每一行代表一条记录。表可以看作某个实体的集合。
具体代码如下:
import pymysql
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='root',
db='flask',
charset='utf8'
cur = conn.cursor()
def save_to_mysql(course_list):
course_data = []
for item in course_list:
course_value = (0, item["productId"], item["productName"],item["lectorName"], item["score"])
course_data.append(course_value)
string_s = ('%s,' * 5)[:-1]
sql_course = f"insert into course values ({string_s})"
cur.executemany(sql_course, course_data)
def main(index):
content = get_json(index) # 获取json数据
course_list = get_content(content) # 获取第index页的50条件记录
save_to_mysql(course_list)
import time
if __name__ == "__main__":
print("开始执行")
start = time.time()
total_page_count = get_json(1)["result"]["query"]["totlePageCount"] # 总页数
for index in range(1, total_page_count + 1):
main(index)
cur.close()
conn.commit()
conn.close()
end = time.time()
print(f"执行结束,程序耗时{end-start}秒")
保存的数据如下:
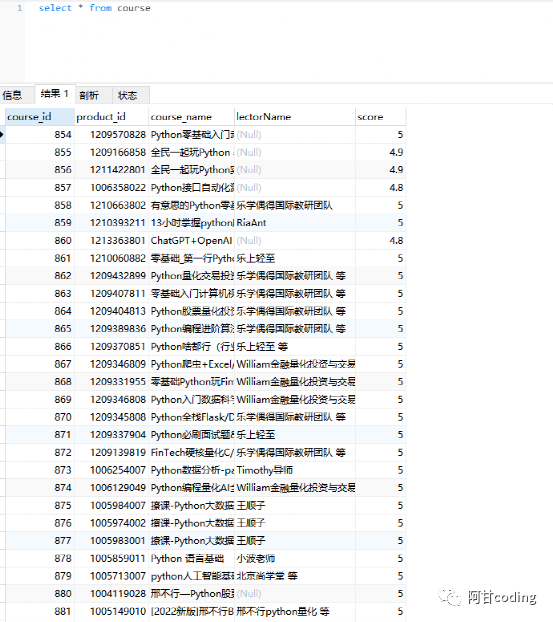
MongoDB文档存储
MongoDB是一种非关系型数据库NoSQL,全称Not Only SQL,意为不仅仅是SQL。NoSQL是基于键值对的,而且不需要经过SQL层的解析,数据之间没有耦合性,性能非常高。对于爬虫的数据存储来说,一条数据可能存在因某些字段提取失败而缺失的情况,而且数据可能随时调整。另外数据之间还存在嵌套关系,如果使用关系型数据库存储这些数据,一是需要提前建表,二是如果数据存在嵌套关系,还需要进行序列化操作才可以存储,这非常不方便。如果使用非关系型数据库,就可以避免这些麻烦,更简单、高效。
代码如下:
import pymongo
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'course'
MONGO_COLLECTION_NAME = 'course'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client['course']
collection = db['course']
defsave_data(item):
collection.update_one({
'name':item['productName']
},{
'$set':item
},upsert=True)
if __name__ == '__main__':
total_page_count = get_json(1)["result"]["query"]["totlePageCount"] # 总页数
for page in range(1, total_page_count + 1):
content = get_content(get_json(page))
for item in content:
save_data(item)
保存的数据如下:
来源:
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
|

 窥视卡
窥视卡 雷达卡
雷达卡

 发表于 2023-4-29 10:49:54
发表于 2023-4-29 10:49:54 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜