1925
5775
研究生
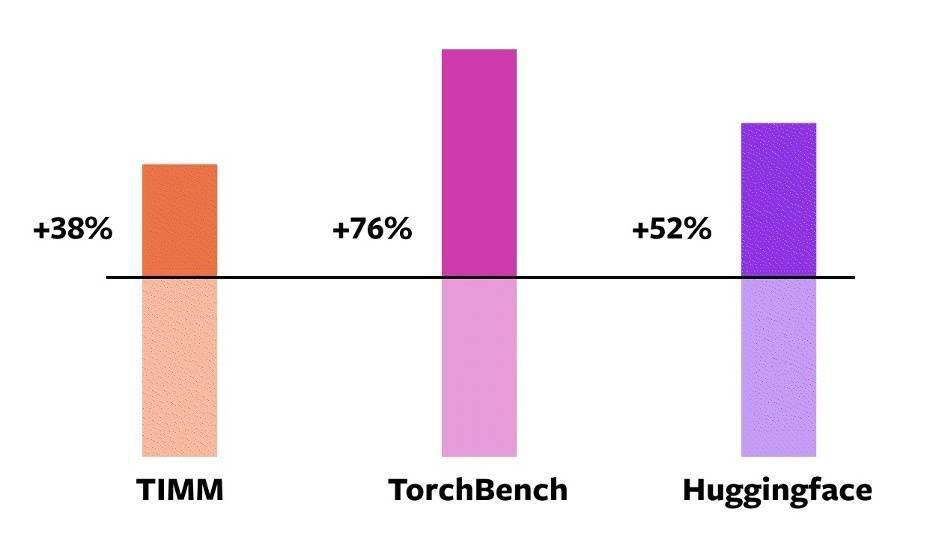
我们通过使用自定义内核和 torch.compile 的组合,使用 Accelerated PyTorch 2 transformer 实现了训练 transformer 模型的大幅加速,特别是大语言模型。
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页

 窥视卡
窥视卡 雷达卡
雷达卡

 发表于 2023-4-27 19:14:22
发表于 2023-4-27 19:14:22


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜